Introduction to programming artificial neural networks#
Tutorial for Methods In Neuroscience at Dartmouth (MIND) 2023#
This tutorial offers an introduction to programming your own customized artificial neural network (ANN) for the first time. It is based on the popular ANN programming framework PyTorch. You will build up an ANN to perform regression, starting from a very simple network and working up step-by-step to a more complex one.
This notebook focuses on the implementation of ANNs. If you’re interested in a complementary conceptual introduction to ANNs, their potential uses in social neuroscience, and their limitations, please consider my preprint with Beau Sievers.
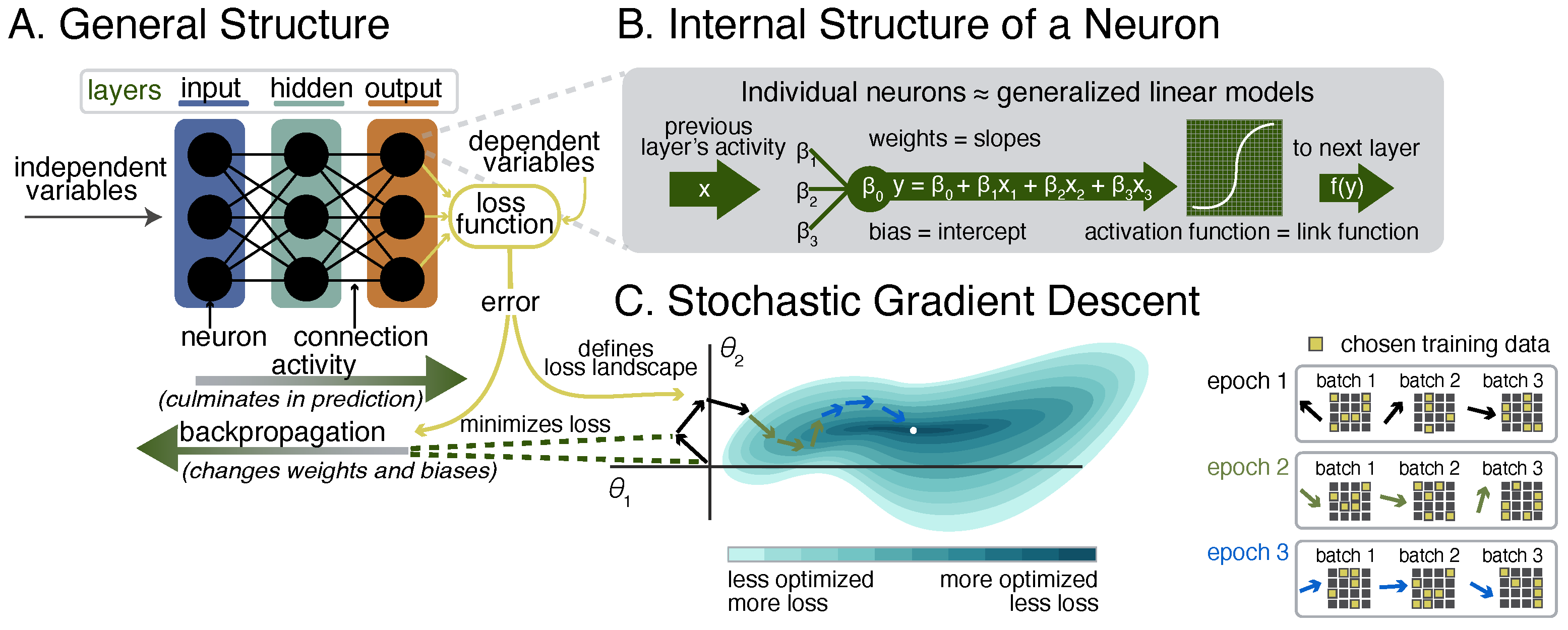
The figure below, created by Lindsey Tepfer for the aforementioned preprint, illustrates the (A) general structure of ANNs, (B) the internal structure of individual units, which approximate generalized linear models, and (C) the training process using stochastic gradient descent via backpropagation. The terminology in this figure will reappear throughout the tutorial.
Setup#
This section includes the import statements for the packages/functions we’ll need here, detection of the available hardware for ANN fitting, and code to simulate the artificial data we’ll be using.
Import packages#
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm
import torch
from torch import nn
from torch.utils.data import DataLoader, TensorDataset
import torch.nn.functional as F
import statsmodels.api as sm
from sklearn.metrics import r2_score, mean_squared_error
%matplotlib inline
Detect and set hardware device#
Depending on where you run your notebook, you may be able to take advantage of different hardware. If a cuda-enable graphics card is available, this will be preferred. Mac chipsets (MPS) and traditional processors (CPU) are the fallback options. On Colab, you may want to change your runtime type to take advantage of the GPU runtimes they offer.
device = (
"cuda"
if torch.cuda.is_available()
else "mps"
if torch.backends.mps.is_available()
else "cpu"
)
print(f"Using {device} device")
Using cuda device
Simulate data#
# set random seeds
torch.manual_seed(0) # pytorch's random seed
np.random.seed(0) # numpy's random seed
# linear relationship
# set sample sizes
ntrain = 100000 # training
ntest = 1000 # testing
nval = 10000 # validation
# the x-variable is drawn from a standard normal distribution
x_train = np.random.normal(0,1,ntrain)
x_test = np.random.normal(0,1,ntest)
x_val = np.random.normal(0,1,nval)
# this y-variable is a linear function of the x-variable
# a bit a Gaussian noise is added, as well as a constant slope and intercept
y_lin_train = x_train*1.5 + np.random.normal(0,.1,ntrain) + 1
y_lin_test = x_test*1.5 + np.random.normal(0,.1,ntest) + 1
# nonlinear relationship
# the second y-variable is a quadratic function of the x-variable
y_non_train = np.power(x_train,2) + np.random.normal(0,.1,ntrain)
y_non_test = np.power(x_test,2) + np.random.normal(0,.1,ntest)
y_non_val = np.power(x_val,2) + np.random.normal(0,.1,nval)
# reshape so as to avoid confusing pytorch with 1d data
x_train.shape = (ntrain, 1)
y_lin_train.shape = (ntrain, 1)
y_non_train.shape = (ntrain, 1)
x_test.shape = (ntest, 1)
y_lin_test.shape = (ntest, 1)
y_non_test.shape = (ntest, 1)
x_val.shape = (nval, 1)
y_non_val.shape = (nval, 1)
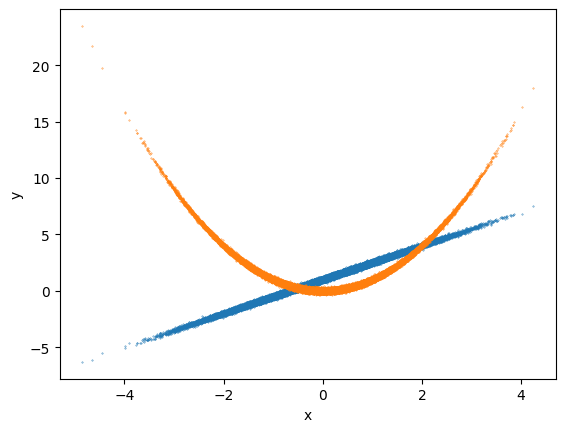
# plot simulated (training) data
plt.scatter(x_train,y_lin_train,s=.1)
plt.scatter(x_train,y_non_train,s=.1)
plt.xlabel("x");
plt.ylabel("y");
Simple linear regression#
We’ll begin by showing how ANNs can approximate simple (OLS) regression. In fact, ANNs can approximate nearly all of the modeling techniques in the typical psych/neuro toolkit, ranging from this simple case up through things like factor analysis and beyond.
# define model with a single linear unit which takes one input
model1 = nn.Linear(1, 1)
# define loss (error) function as mean square error
# this is similar to ordinary least squares regression
loss = nn.MSELoss()
# define optimizers as stochastic gradient descent (SGD)
# feed in parameters of the model to be optimized and the learning rate
# (in most cases, we would probably use a much lower learning rate)
optimizer = torch.optim.SGD(model1.parameters(),lr=.5)
Now let’s train the model:
nepoch = 10 # epochs = how many times the model sees the dataset
# note that we're not actually using the GPU yet - see the next example for that
for epoch in range(nepoch):
# convert inputs and targets to torch tensors
inputs = torch.from_numpy(np.float32(x_train))
targets = torch.from_numpy(np.float32(y_lin_train))
# propagate activity forward through network to make prediction
outputs = model1(inputs)
# compute loss (error) of predictions
curloss = loss(outputs, targets)
# backpropagate errors to change weights and biases via SGD
optimizer.zero_grad()
curloss.backward()
optimizer.step()
# print
if (epoch+1) % 1 == 0:
print ('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, nepoch, curloss.item()))
Epoch [1/10], Loss: 2.4881
Epoch [2/10], Loss: 0.0100
Epoch [3/10], Loss: 0.0100
Epoch [4/10], Loss: 0.0100
Epoch [5/10], Loss: 0.0100
Epoch [6/10], Loss: 0.0100
Epoch [7/10], Loss: 0.0100
Epoch [8/10], Loss: 0.0100
Epoch [9/10], Loss: 0.0100
Epoch [10/10], Loss: 0.0100
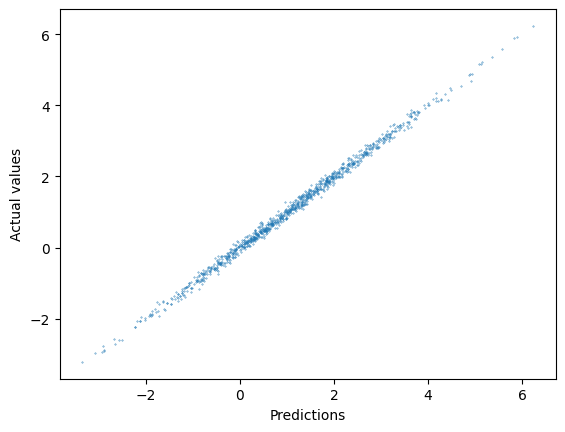
Now that we’ve trained the model, let’s take a look at its out-of-sample performance on our simulated test set. To do this, we’ll make predictions for the test set, and compare them to the actual test values using R2 and RMSE, as well as plotting them against one another. As you’ll see, the R2 is near perfect, and the RMSE is just about equal to the SD of the noise we injected when simulating the data. In other words, the model is performing as well as it could.
# plot the relationship between predicted and actual test values
ypred = model1(torch.from_numpy(np.float32(x_test))).detach().numpy()
plt.scatter(ypred,y_lin_test,s=.1)
plt.xlabel("Predictions");
plt.ylabel("Actual values");
# print out performance metrics
print(r2_score(y_lin_test,ypred))
print(np.sqrt(mean_squared_error(y_lin_test,ypred)))
0.9957496739688491
0.09758071680706164
Now let’s compare the results to an ordinary least squares (OLS) regression - the more traditional way to model this sort of data in psychology and neuroscience. First, we’ll print out the weight and bias of the sole unit in the neural network, and then fit and print the equivalent parameters (slope and intercept) of the OLS regression, using the statsmodels package.
# print out weight and bias parameters
for name, param in model1.named_parameters():
if param.requires_grad:
print(name, param.data)
weight tensor([[1.5001]])
bias tensor([1.0004])
# observe that a traditional OLS regression learns the same parameter values
ols = sm.OLS(y_lin_train,sm.add_constant(x_train))
res = ols.fit()
print(res.summary())
OLS Regression Results
==============================================================================
Dep. Variable: y R-squared: 0.996
Model: OLS Adj. R-squared: 0.996
Method: Least Squares F-statistic: 2.242e+07
Date: Fri, 04 Aug 2023 Prob (F-statistic): 0.00
Time: 03:48:42 Log-Likelihood: 88450.
No. Observations: 100000 AIC: -1.769e+05
Df Residuals: 99998 BIC: -1.769e+05
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 1.0004 0.000 3166.125 0.000 1.000 1.001
x1 1.5001 0.000 4735.113 0.000 1.499 1.501
==============================================================================
Omnibus: 0.830 Durbin-Watson: 2.004
Prob(Omnibus): 0.660 Jarque-Bera (JB): 0.840
Skew: 0.006 Prob(JB): 0.657
Kurtosis: 2.991 Cond. No. 1.00
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
As you can see, despite the different implementation, an ANN can yield effectively identical results as familiar OLS regression, under idealized circumstances.
Nonlinear regression#
In the previous section, we saw how an ANN can be used to approximate a simple linear regression. However, one of the main advantages of ANNs is that they can model highly nonlinear relationships. In this section, we’ll start to see how that can be achieved.
Trying the linear model on nonlinear data#
First, we will try to fit our simulated nonlinear (bivariate quadratic) data using the same model architecture we tried in this last section. This time we’ll code up that model in a different way (i.e., a more object-oriented approach, instead of the more imperative approach above).
# define model architecture
class SimpleLinearANN(nn.Module):
def __init__(self):
super().__init__()
# the "Sequential" class offers a convenient way to fit many simple ANNs
self.layer_stack = nn.Sequential(
nn.Linear(1,1)
)
def forward(self, x):
pred = self.layer_stack(x)
return pred
model2 = SimpleLinearANN().to(device)
print(model2)
SimpleLinearANN(
(layer_stack): Sequential(
(0): Linear(in_features=1, out_features=1, bias=True)
)
)
We’ll also define our training and testing more functionally now, so that we can reuse these functions later.
# define training function
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
model.train()
for batch, (X, y) in enumerate(dataloader):
# note that we're actually using the GPU here
X, y = X.to(device), y.to(device)
# Compute prediction error
pred = model(X)
loss = loss_fn(pred, y)
# Backpropagation
loss.backward()
optimizer.step()
optimizer.zero_grad()
if batch % 100 == 0:
loss, current = loss.item(), (batch + 1) * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
# define test function
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
test_loss, r2 = 0, 0 # evaluate loss (MSE, and R^2)
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
test_loss += loss_fn(pred, y).item()
r2 += 1 - torch.sum((y-pred)**2) / torch.sum(y **2)
test_loss /= num_batches
r2 /= num_batches
print(f"Test performance: \n R^2: {r2:>8f}, RMSE: {np.sqrt(test_loss):>8f} \n")
return r2.cpu().numpy(), test_loss
Next, we’ll put our simulated data into pytorch’s dataloader - an iterable class that supports batching (breaking up the overall dataset into smaller batches), and shuffling (randomizing the order of that data), among other features. Generally it’s a good idea to choose a batch size that is a power of 2 (for memory efficiency), and to shuffle your data to prevent catastrophic forgetting that can come from showing the model a bunch of similar examples in a row.
# turn our numpy variables into pytorch datasets
xtrain_tensor = torch.from_numpy(np.float32(x_train))
ytrain_tensor = torch.from_numpy(np.float32(y_non_train))
nonlinear_training_data = TensorDataset(xtrain_tensor, ytrain_tensor)
xtest_tensor = torch.from_numpy(np.float32(x_test))
ytest_tensor = torch.from_numpy(np.float32(y_non_test))
nonlinear_testing_data = TensorDataset(xtest_tensor, ytest_tensor)
xval_tensor = torch.from_numpy(np.float32(x_val))
yval_tensor = torch.from_numpy(np.float32(y_non_val))
val_data = TensorDataset(xval_tensor, yval_tensor)
# put the datasets into the dataloader
train_dataloader = DataLoader(nonlinear_training_data, batch_size=64, shuffle=True)
test_dataloader = DataLoader(nonlinear_testing_data, batch_size=64, shuffle=True)
val_dataloader = DataLoader(val_data, batch_size=64, shuffle=True)
# new we'll train the model (note that loss does not seem steadily to improve)
loss = nn.MSELoss()
optimizer = torch.optim.SGD(model2.parameters(),lr=.5)
epochs = 3
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train(train_dataloader, model2, loss, optimizer)
print("Done!")
Epoch 1
-------------------------------
loss: 3.297604 [ 64/100000]
loss: 2.270447 [ 6464/100000]
loss: 2.475495 [12864/100000]
loss: 2.216384 [19264/100000]
loss: 2.483925 [25664/100000]
loss: 3.111267 [32064/100000]
loss: 2.170219 [38464/100000]
loss: 3.388379 [44864/100000]
loss: 4.701067 [51264/100000]
loss: 1.805016 [57664/100000]
loss: 1.798295 [64064/100000]
loss: 2.880607 [70464/100000]
loss: 1.875021 [76864/100000]
loss: 1.566702 [83264/100000]
loss: 1.444066 [89664/100000]
loss: 3.873803 [96064/100000]
Epoch 2
-------------------------------
loss: 1.891131 [ 64/100000]
loss: 1.695512 [ 6464/100000]
loss: 1.589921 [12864/100000]
loss: 1.268939 [19264/100000]
loss: 1.167627 [25664/100000]
loss: 1.327818 [32064/100000]
loss: 1.701994 [38464/100000]
loss: 0.960532 [44864/100000]
loss: 1.701208 [51264/100000]
loss: 5.352643 [57664/100000]
loss: 1.198715 [64064/100000]
loss: 2.584759 [70464/100000]
loss: 2.101575 [76864/100000]
loss: 2.096920 [83264/100000]
loss: 3.844053 [89664/100000]
loss: 2.158092 [96064/100000]
Epoch 3
-------------------------------
loss: 2.072096 [ 64/100000]
loss: 2.084110 [ 6464/100000]
loss: 2.557325 [12864/100000]
loss: 1.547599 [19264/100000]
loss: 1.849058 [25664/100000]
loss: 2.230387 [32064/100000]
loss: 0.976333 [38464/100000]
loss: 0.971154 [44864/100000]
loss: 2.253049 [51264/100000]
loss: 1.980433 [57664/100000]
loss: 1.413823 [64064/100000]
loss: 3.303815 [70464/100000]
loss: 3.310146 [76864/100000]
loss: 1.572646 [83264/100000]
loss: 2.585217 [89664/100000]
loss: 2.679968 [96064/100000]
Done!
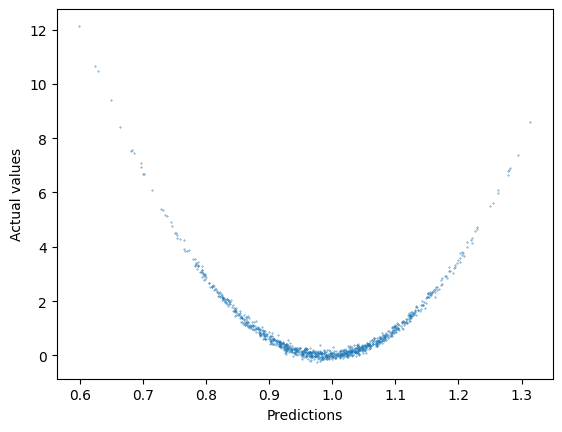
As we can see below, the performance of the linear model is poor, and it is not capturing the nonlinear relationship in the data.
# performance metrics
perf = test(test_dataloader, model2, loss)
Test performance:
R^2: 0.300736, RMSE: 1.491297
# plotting actual values vs. predictions
ypred = model2(torch.from_numpy(np.float32(x_test)).to(device)).cpu().detach().numpy()
plt.scatter(ypred,y_non_test,s=.1)
plt.xlabel("Predictions");
plt.ylabel("Actual values");
Shallow/wide nonlinear ANN#
As we’ve seen, linear regression can’t capture a nonlinear relationship. The traditional approach to dealiung with this would be to do some manual feature engineering, like creating a quadratic term by multiplying our “x” by itself. This approach would actually work fine with the simulated data we’re playing with here. However, it does not scale up well to datasets with more variables and more complex nonlinearities. A major part of the appeal of ANNs is that - under the right circumstances - they can learn optimal nonlinear mappings between inputs and outputs for us.
Most of the ANNs you’ll see making news these days are “deep” neural networks. The deep in this phrase refers to stacking a large number of layers on top of each other. However, before we do that, it’s worth taking a look at “shallow” neural networks. Shallow networks can actually do everything that deep nets can do - in principle. In practice, they tend to do this in a different way, that is often less than ideal. Specifically, shallow networks are memorization machines. They learn many simple local approximations to the relationship between inputs and outputs. With enough capacity, they can memorize an arbitrarily complex relationship, making them universal function approximators. Let’s see how this works! Below we’ll train a shallow ANN with many more units, and a nonlinear activation function (ReLU - probably the most popular nonlinear activation function for ANNs).
# define model architecture
class ShallowWideANN(nn.Module):
def __init__(self):
super().__init__()
self.layer_stack = nn.Sequential(
nn.Linear(1,1000), ## layer with 1000 units!
nn.ReLU(), ## apply a nonlinear activation function
nn.Linear(1000,1), ## single linear output
)
def forward(self, x):
pred = self.layer_stack(x)
return pred
model3 = ShallowWideANN().to(device)
print(model3)
ShallowWideANN(
(layer_stack): Sequential(
(0): Linear(in_features=1, out_features=1000, bias=True)
(1): ReLU()
(2): Linear(in_features=1000, out_features=1, bias=True)
)
)
# new we'll train the model
# note that we've tuned down the learning rate
loss = nn.MSELoss()
optimizer = torch.optim.SGD(model3.parameters(),lr=.001)
epochs = 3
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train(train_dataloader, model3, loss, optimizer)
print("Done!")
Epoch 1
-------------------------------
loss: 2.869074 [ 64/100000]
loss: 0.120316 [ 6464/100000]
loss: 0.041936 [12864/100000]
loss: 0.037916 [19264/100000]
loss: 0.028931 [25664/100000]
loss: 0.040988 [32064/100000]
loss: 0.178121 [38464/100000]
loss: 0.031798 [44864/100000]
loss: 0.067478 [51264/100000]
loss: 0.031456 [57664/100000]
loss: 0.021962 [64064/100000]
loss: 0.018875 [70464/100000]
loss: 0.023422 [76864/100000]
loss: 0.053598 [83264/100000]
loss: 0.023415 [89664/100000]
loss: 0.033236 [96064/100000]
Epoch 2
-------------------------------
loss: 0.016946 [ 64/100000]
loss: 0.024055 [ 6464/100000]
loss: 0.046232 [12864/100000]
loss: 0.016391 [19264/100000]
loss: 0.019041 [25664/100000]
loss: 0.017909 [32064/100000]
loss: 0.016895 [38464/100000]
loss: 0.022496 [44864/100000]
loss: 0.050606 [51264/100000]
loss: 0.016962 [57664/100000]
loss: 0.020621 [64064/100000]
loss: 0.017214 [70464/100000]
loss: 0.021813 [76864/100000]
loss: 0.025850 [83264/100000]
loss: 0.013514 [89664/100000]
loss: 0.026187 [96064/100000]
Epoch 3
-------------------------------
loss: 0.021621 [ 64/100000]
loss: 0.015872 [ 6464/100000]
loss: 0.014883 [12864/100000]
loss: 0.022556 [19264/100000]
loss: 0.016457 [25664/100000]
loss: 0.013740 [32064/100000]
loss: 0.019121 [38464/100000]
loss: 0.018989 [44864/100000]
loss: 0.034832 [51264/100000]
loss: 0.024770 [57664/100000]
loss: 0.013531 [64064/100000]
loss: 0.013870 [70464/100000]
loss: 0.018242 [76864/100000]
loss: 0.182599 [83264/100000]
loss: 0.021299 [89664/100000]
loss: 0.020903 [96064/100000]
Done!
# performance metrics
# the shallow network is doing quite well!
perf = test(test_dataloader, model3, loss)
Test performance:
R^2: 0.990787, RMSE: 0.171964
# plotting actual values vs. predictions
ypred = model3(torch.from_numpy(np.float32(x_test)).to(device)).cpu().detach().numpy()
plt.scatter(ypred,y_non_test,s=.1)
plt.xlabel("Predictions");
plt.ylabel("Actual values");
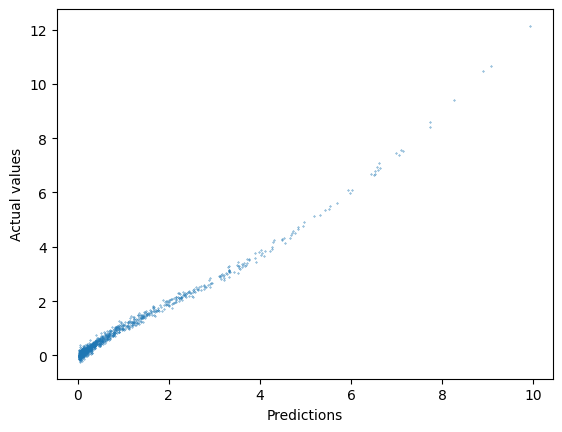
As you can see, the shallow network has learned a pretty good approximation of the nonlinear relationship in our data, just by memorizing small bits of it in each unit. The results here aren’t perfect, but with infinite data and infinite units, a shallow network can get arbitrarily close to perfection. In our more mundane world of limited data and models, deep neural networks typically offer a better solution.
Deep neural network#
In the example below, we’ll use far fewer units to achieve similar performance, via a deep neural network. This network features 5 ReLU layers, with units decreasing in power of two. The final layer is a single linear unit, as in previous cases. An important addition here is batch normalization after each ReLU activation. Batch normalization is basically like z-scoring the data. This is really helpful to prevent what’s known as the “exploding gradient” problem. Basically, nonlinear transformations have the potential to make some numbers really huge (or tiny) and this can cause problems for numerical computing with float point representations. Batch normalization helps to mitigate this problem, serving as a sort of regularization that improves training.
# define model architecture
class DeepANN(nn.Module):
def __init__(self):
super().__init__()
self.layer_stack = nn.Sequential(
nn.Linear(1,32),
nn.ReLU(),
nn.BatchNorm1d(32),
nn.Linear(32,16),
nn.ReLU(),
nn.BatchNorm1d(16),
nn.Linear(16,8),
nn.ReLU(),
nn.BatchNorm1d(8),
nn.Linear(8,4),
nn.ReLU(),
nn.BatchNorm1d(4),
nn.Linear(4,2),
nn.ReLU(),
nn.BatchNorm1d(2),
nn.Linear(2,1)
)
def forward(self, x):
pred = self.layer_stack(x)
return pred
model4 = DeepANN().to(device)
print(model4)
DeepANN(
(layer_stack): Sequential(
(0): Linear(in_features=1, out_features=32, bias=True)
(1): ReLU()
(2): BatchNorm1d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): Linear(in_features=32, out_features=16, bias=True)
(4): ReLU()
(5): BatchNorm1d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(6): Linear(in_features=16, out_features=8, bias=True)
(7): ReLU()
(8): BatchNorm1d(8, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(9): Linear(in_features=8, out_features=4, bias=True)
(10): ReLU()
(11): BatchNorm1d(4, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(12): Linear(in_features=4, out_features=2, bias=True)
(13): ReLU()
(14): BatchNorm1d(2, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(15): Linear(in_features=2, out_features=1, bias=True)
)
)
# new we'll train the model
loss = nn.MSELoss()
optimizer = torch.optim.SGD(model4.parameters(),lr=.01)
epochs = 3
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train(train_dataloader, model4, loss, optimizer)
print("Done!")
Epoch 1
-------------------------------
loss: 4.667707 [ 64/100000]
loss: 0.989088 [ 6464/100000]
loss: 0.216513 [12864/100000]
loss: 0.264145 [19264/100000]
loss: 0.306660 [25664/100000]
loss: 0.456342 [32064/100000]
loss: 0.057279 [38464/100000]
loss: 0.060745 [44864/100000]
loss: 0.394866 [51264/100000]
loss: 0.418425 [57664/100000]
loss: 0.314052 [64064/100000]
loss: 0.173316 [70464/100000]
loss: 0.039098 [76864/100000]
loss: 0.173622 [83264/100000]
loss: 0.153746 [89664/100000]
loss: 0.228229 [96064/100000]
Epoch 2
-------------------------------
loss: 0.071922 [ 64/100000]
loss: 0.055156 [ 6464/100000]
loss: 0.248226 [12864/100000]
loss: 0.049417 [19264/100000]
loss: 0.040127 [25664/100000]
loss: 0.057625 [32064/100000]
loss: 0.714862 [38464/100000]
loss: 0.200428 [44864/100000]
loss: 0.236930 [51264/100000]
loss: 0.031537 [57664/100000]
loss: 0.179619 [64064/100000]
loss: 0.115763 [70464/100000]
loss: 0.201975 [76864/100000]
loss: 0.044374 [83264/100000]
loss: 0.070829 [89664/100000]
loss: 0.019935 [96064/100000]
Epoch 3
-------------------------------
loss: 0.119832 [ 64/100000]
loss: 0.057674 [ 6464/100000]
loss: 0.081795 [12864/100000]
loss: 0.079885 [19264/100000]
loss: 0.036620 [25664/100000]
loss: 0.088968 [32064/100000]
loss: 0.167877 [38464/100000]
loss: 0.203338 [44864/100000]
loss: 0.018583 [51264/100000]
loss: 0.209267 [57664/100000]
loss: 0.175974 [64064/100000]
loss: 0.060453 [70464/100000]
loss: 0.039461 [76864/100000]
loss: 0.105169 [83264/100000]
loss: 0.085562 [89664/100000]
loss: 0.035103 [96064/100000]
Done!
# performance metrics
perf = test(test_dataloader, model4, loss)
Test performance:
R^2: 0.980514, RMSE: 0.292389
# plotting actual values vs. predictions
ypred = model4(torch.from_numpy(np.float32(x_test)).to(device)).cpu().detach().numpy()
plt.scatter(ypred,y_non_test,s=.1)
plt.xlabel("Predictions");
plt.ylabel("Actual values");

# compute the number of trainable parameters in shallow and deep net
m3p = sum(p.numel() for p in model3.parameters() if p.requires_grad)
m4p = sum(p.numel() for p in model4.parameters() if p.requires_grad)
print("Shallow net parameter number: " + str(m3p))
print("Deep net parameter number: " + str(m4p))
Shallow net parameter number: 3001
Deep net parameter number: 901
As you can see, the deep net has achieved similar performance to the shallow network, with only a fraction of the parameters!
Bells and whistles#
The deep net we used in the previous example was quite “bare bones” by contemporary standards. In practice, most deep nets rely on a variety of other features to improve their performance. Showcasing all of these features is beyond the scope of this tutorial, but the example below demonstrates a few popular examples, including:
Skip-layer connections: In the most prototypical case, each layer in an ANN is connected only to the adjacent layers (e.g., layer 2 is connected to layer 1 and layer 3). This is known as a sequential structure, and the sequential class in pytorch makes this very convenient. However, some of the most important milestones in deep learning have been achieved by abandoning this simple structure. For example, resnets (residual networks) are an architecture that allowed computer vision to equal humans in tasks like object identification. These networks rely on connections that skip layers. The network below demonstrates this: in addition to receiving input from the previous layer, the final outputs here also receive input from the first layer. The potential of the nn.Module class extends well beyond this too: it can be used to stitch together different ANNs performing different tasks in different ways.
Alternate activation functions: Although ReLU is probably the most popular default choice of nonlinear activation function, there are many options to choose from, and some may be better suited to particular problems. Here we demonstrate the use of the hyperbolic tangent (tanh) function as an alternative to ReLU. For niche applications (e.g., cognitive modeling) you could even craft your own bespoke activation functions.
Dropout: ANNs can use the same regularization, like ridge/lasso, that typical linear models can use. However, dropout is a method unique to ANNs. This method effectively “lesions” a random subset of units during the forward pass of the model. This forces the model to acquire a more robust structure - effectively, many different assemblies that can accomplish the same end goal - that tends to reduce overfitting.
Early stopping: Another strategy to prevent overfitting is early stopping. This strategy only makes sense for optimization strategies that proceed in a sequential manner (like gradient descent) rather than a single step of matrix math. Early stopping compares the performance of the model in training set to its performance in a validation set. As long as validation performance continues to improve, the model keep training. But when training performance improves while validation performance stalls, this is a sign of overfitting. Early stopping tracks this potential divergence between training and validation, and stops training when validation performance stops improving.
# define model architecture
class FancyANN(nn.Module):
def __init__(self, ninput=1, noutput=1, nhlayer=5, fextint=True):
super().__init__()
self.fextint = 0
if fextint:
self.fextint = 2**nhlayer
self.nhlayer = nhlayer
self.layerlist = nn.ModuleList()
for i in range(nhlayer):
if i == 0:
self.layerlist.append(nn.Linear(ninput,2**(nhlayer-i)))
else:
self.layerlist.append(nn.Linear(2**(nhlayer-i+1),2**(nhlayer-i)))
self.layerlist.append(nn.Tanh()) # here's our alternative activation function (tanh)
self.layerlist.append(nn.BatchNorm1d(2**(nhlayer-i)))
self.layerlist.append(nn.Dropout(p=.01)) ## here's where we add dropout
self.layerlist.append(nn.Linear(self.fextint+2,noutput))
def forward(self, x):
for i in range(len(self.layerlist)-1):
x = self.layerlist[i](x)
if i == 2:
x0 = torch.clone(x)
pred = self.layerlist[-1](torch.cat((x0,x),1)) ## here's where the first layer and penultimate layer get joined together as inputs to the final layer
return pred
model5 = FancyANN().to(device)
print(model5)
FancyANN(
(layerlist): ModuleList(
(0): Linear(in_features=1, out_features=32, bias=True)
(1): Tanh()
(2): BatchNorm1d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): Dropout(p=0.01, inplace=False)
(4): Linear(in_features=32, out_features=16, bias=True)
(5): Tanh()
(6): BatchNorm1d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): Dropout(p=0.01, inplace=False)
(8): Linear(in_features=16, out_features=8, bias=True)
(9): Tanh()
(10): BatchNorm1d(8, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(11): Dropout(p=0.01, inplace=False)
(12): Linear(in_features=8, out_features=4, bias=True)
(13): Tanh()
(14): BatchNorm1d(4, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(15): Dropout(p=0.01, inplace=False)
(16): Linear(in_features=4, out_features=2, bias=True)
(17): Tanh()
(18): BatchNorm1d(2, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(19): Dropout(p=0.01, inplace=False)
(20): Linear(in_features=34, out_features=1, bias=True)
)
)
# this class defines the logic of early stopping
# higher patience means that improvement on the validation set has to stall for longer before training is terminated
class EarlyStopper:
def __init__(self, patience=1, min_delta=0):
self.patience = patience
self.min_delta = min_delta
self.counter = 0
self.min_validation_loss = np.inf
def early_stop(self, validation_loss):
if validation_loss < self.min_validation_loss:
self.min_validation_loss = validation_loss
self.counter = 0
elif validation_loss > (self.min_validation_loss + self.min_delta):
self.counter += 1
if self.counter >= self.patience:
return True
return False
# new we'll train the model
early_stopper = EarlyStopper(patience=3, min_delta=0)
loss = nn.MSELoss()
optimizer = torch.optim.Adam(model5.parameters(),lr=.0001) # we're trying a different optimizer here too (ADAM)
epochs = 100 # this is just an upperbound - the actual epoch # is determined by early stopping
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train(train_dataloader, model5, loss, optimizer)
val_loss = test(val_dataloader, model5, loss)[1]
if early_stopper.early_stop(val_loss):
break
print("Done!")
Epoch 1
-------------------------------
loss: 3.888131 [ 64/100000]
loss: 3.917098 [ 6464/100000]
loss: 2.937879 [12864/100000]
loss: 5.071634 [19264/100000]
loss: 3.716036 [25664/100000]
loss: 2.398747 [32064/100000]
loss: 1.351015 [38464/100000]
loss: 1.365817 [44864/100000]
loss: 1.875856 [51264/100000]
loss: 1.061013 [57664/100000]
loss: 1.337905 [64064/100000]
loss: 1.853628 [70464/100000]
loss: 0.764149 [76864/100000]
loss: 0.915835 [83264/100000]
loss: 0.340542 [89664/100000]
loss: 0.346805 [96064/100000]
Test performance:
R^2: 0.780519, RMSE: 0.845239
Epoch 2
-------------------------------
loss: 0.396910 [ 64/100000]
loss: 0.205753 [ 6464/100000]
loss: 0.607033 [12864/100000]
loss: 1.113464 [19264/100000]
loss: 0.097006 [25664/100000]
loss: 0.100322 [32064/100000]
loss: 0.931997 [38464/100000]
loss: 0.178657 [44864/100000]
loss: 0.537316 [51264/100000]
loss: 0.205982 [57664/100000]
loss: 0.245557 [64064/100000]
loss: 0.080524 [70464/100000]
loss: 0.222449 [76864/100000]
loss: 0.213365 [83264/100000]
loss: 0.096103 [89664/100000]
loss: 0.591012 [96064/100000]
Test performance:
R^2: 0.979044, RMSE: 0.285466
Epoch 3
-------------------------------
loss: 0.064183 [ 64/100000]
loss: 0.243895 [ 6464/100000]
loss: 0.307392 [12864/100000]
loss: 0.179972 [19264/100000]
loss: 0.183356 [25664/100000]
loss: 0.188181 [32064/100000]
loss: 0.091715 [38464/100000]
loss: 0.677460 [44864/100000]
loss: 0.177787 [51264/100000]
loss: 0.066920 [57664/100000]
loss: 0.166385 [64064/100000]
loss: 0.066744 [70464/100000]
loss: 0.129679 [76864/100000]
loss: 0.137251 [83264/100000]
loss: 0.135885 [89664/100000]
loss: 0.153805 [96064/100000]
Test performance:
R^2: 0.986803, RMSE: 0.227382
Epoch 4
-------------------------------
loss: 0.329610 [ 64/100000]
loss: 0.309667 [ 6464/100000]
loss: 0.238928 [12864/100000]
loss: 0.049671 [19264/100000]
loss: 0.172278 [25664/100000]
loss: 0.167100 [32064/100000]
loss: 0.202609 [38464/100000]
loss: 0.105646 [44864/100000]
loss: 0.214544 [51264/100000]
loss: 0.181315 [57664/100000]
loss: 0.105952 [64064/100000]
loss: 0.054405 [70464/100000]
loss: 0.230735 [76864/100000]
loss: 0.109101 [83264/100000]
loss: 0.124816 [89664/100000]
loss: 0.099370 [96064/100000]
Test performance:
R^2: 0.988537, RMSE: 0.204467
Epoch 5
-------------------------------
loss: 0.063645 [ 64/100000]
loss: 0.123861 [ 6464/100000]
loss: 0.083427 [12864/100000]
loss: 0.250894 [19264/100000]
loss: 0.298372 [25664/100000]
loss: 0.049779 [32064/100000]
loss: 0.054952 [38464/100000]
loss: 0.233167 [44864/100000]
loss: 0.297191 [51264/100000]
loss: 0.102348 [57664/100000]
loss: 0.036531 [64064/100000]
loss: 0.079810 [70464/100000]
loss: 0.119193 [76864/100000]
loss: 0.105115 [83264/100000]
loss: 0.118437 [89664/100000]
loss: 0.212578 [96064/100000]
Test performance:
R^2: 0.989374, RMSE: 0.194593
Epoch 6
-------------------------------
loss: 0.104637 [ 64/100000]
loss: 0.124436 [ 6464/100000]
loss: 0.227147 [12864/100000]
loss: 0.285004 [19264/100000]
loss: 0.306534 [25664/100000]
loss: 0.126568 [32064/100000]
loss: 0.062833 [38464/100000]
loss: 0.070517 [44864/100000]
loss: 0.049845 [51264/100000]
loss: 0.080152 [57664/100000]
loss: 0.142207 [64064/100000]
loss: 0.082779 [70464/100000]
loss: 0.067380 [76864/100000]
loss: 0.080468 [83264/100000]
loss: 0.099579 [89664/100000]
loss: 0.149001 [96064/100000]
Test performance:
R^2: 0.991916, RMSE: 0.170523
Epoch 7
-------------------------------
loss: 0.090363 [ 64/100000]
loss: 0.105410 [ 6464/100000]
loss: 0.040804 [12864/100000]
loss: 0.054256 [19264/100000]
loss: 0.027425 [25664/100000]
loss: 0.207500 [32064/100000]
loss: 0.090952 [38464/100000]
loss: 0.086845 [44864/100000]
loss: 0.079099 [51264/100000]
loss: 0.275742 [57664/100000]
loss: 0.028412 [64064/100000]
loss: 0.116104 [70464/100000]
loss: 0.120119 [76864/100000]
loss: 0.070722 [83264/100000]
loss: 0.085920 [89664/100000]
loss: 0.083501 [96064/100000]
Test performance:
R^2: 0.991818, RMSE: 0.170135
Epoch 8
-------------------------------
loss: 0.223899 [ 64/100000]
loss: 0.205298 [ 6464/100000]
loss: 0.073132 [12864/100000]
loss: 1.529429 [19264/100000]
loss: 0.101772 [25664/100000]
loss: 0.157559 [32064/100000]
loss: 0.073842 [38464/100000]
loss: 0.123590 [44864/100000]
loss: 0.053510 [51264/100000]
loss: 0.150473 [57664/100000]
loss: 0.092963 [64064/100000]
loss: 0.050164 [70464/100000]
loss: 0.299292 [76864/100000]
loss: 0.059084 [83264/100000]
loss: 0.048018 [89664/100000]
loss: 0.114542 [96064/100000]
Test performance:
R^2: 0.992695, RMSE: 0.156656
Epoch 9
-------------------------------
loss: 0.048064 [ 64/100000]
loss: 1.965292 [ 6464/100000]
loss: 0.050489 [12864/100000]
loss: 0.111465 [19264/100000]
loss: 0.129185 [25664/100000]
loss: 0.453362 [32064/100000]
loss: 0.169424 [38464/100000]
loss: 0.096436 [44864/100000]
loss: 0.081334 [51264/100000]
loss: 0.086524 [57664/100000]
loss: 0.108220 [64064/100000]
loss: 0.026716 [70464/100000]
loss: 0.330060 [76864/100000]
loss: 0.081770 [83264/100000]
loss: 0.102128 [89664/100000]
loss: 0.380724 [96064/100000]
Test performance:
R^2: 0.992518, RMSE: 0.160280
Epoch 10
-------------------------------
loss: 0.067976 [ 64/100000]
loss: 0.061944 [ 6464/100000]
loss: 0.093701 [12864/100000]
loss: 0.062002 [19264/100000]
loss: 0.124478 [25664/100000]
loss: 0.267889 [32064/100000]
loss: 0.094276 [38464/100000]
loss: 0.100655 [44864/100000]
loss: 0.194106 [51264/100000]
loss: 1.437881 [57664/100000]
loss: 0.037840 [64064/100000]
loss: 0.100686 [70464/100000]
loss: 0.042177 [76864/100000]
loss: 0.150511 [83264/100000]
loss: 0.025171 [89664/100000]
loss: 0.045438 [96064/100000]
Test performance:
R^2: 0.991603, RMSE: 0.166102
Epoch 11
-------------------------------
loss: 0.113018 [ 64/100000]
loss: 0.364865 [ 6464/100000]
loss: 0.086984 [12864/100000]
loss: 0.089000 [19264/100000]
loss: 0.048422 [25664/100000]
loss: 0.111554 [32064/100000]
loss: 0.170104 [38464/100000]
loss: 0.456190 [44864/100000]
loss: 0.430310 [51264/100000]
loss: 0.137799 [57664/100000]
loss: 0.087476 [64064/100000]
loss: 0.034155 [70464/100000]
loss: 0.051317 [76864/100000]
loss: 0.139362 [83264/100000]
loss: 0.162727 [89664/100000]
loss: 0.079858 [96064/100000]
Test performance:
R^2: 0.992894, RMSE: 0.148741
Epoch 12
-------------------------------
loss: 0.156293 [ 64/100000]
loss: 0.093481 [ 6464/100000]
loss: 0.044689 [12864/100000]
loss: 0.069560 [19264/100000]
loss: 0.049289 [25664/100000]
loss: 0.330965 [32064/100000]
loss: 0.060987 [38464/100000]
loss: 0.041339 [44864/100000]
loss: 0.157445 [51264/100000]
loss: 0.097228 [57664/100000]
loss: 0.154629 [64064/100000]
loss: 0.153998 [70464/100000]
loss: 0.262758 [76864/100000]
loss: 0.049504 [83264/100000]
loss: 0.030409 [89664/100000]
loss: 0.068077 [96064/100000]
Test performance:
R^2: 0.992230, RMSE: 0.156347
Epoch 13
-------------------------------
loss: 0.205354 [ 64/100000]
loss: 0.252282 [ 6464/100000]
loss: 0.046880 [12864/100000]
loss: 0.122652 [19264/100000]
loss: 0.040483 [25664/100000]
loss: 0.332348 [32064/100000]
loss: 0.209426 [38464/100000]
loss: 0.071124 [44864/100000]
loss: 0.103392 [51264/100000]
loss: 0.065575 [57664/100000]
loss: 0.078010 [64064/100000]
loss: 0.036993 [70464/100000]
loss: 0.177545 [76864/100000]
loss: 0.105658 [83264/100000]
loss: 0.056419 [89664/100000]
loss: 0.047285 [96064/100000]
Test performance:
R^2: 0.991006, RMSE: 0.164956
Epoch 14
-------------------------------
loss: 0.142373 [ 64/100000]
loss: 0.032840 [ 6464/100000]
loss: 0.054341 [12864/100000]
loss: 0.045234 [19264/100000]
loss: 0.072157 [25664/100000]
loss: 0.146573 [32064/100000]
loss: 0.042619 [38464/100000]
loss: 0.093733 [44864/100000]
loss: 0.126631 [51264/100000]
loss: 0.174637 [57664/100000]
loss: 0.021763 [64064/100000]
loss: 0.069974 [70464/100000]
loss: 0.037953 [76864/100000]
loss: 0.215359 [83264/100000]
loss: 0.056612 [89664/100000]
loss: 0.086736 [96064/100000]
Test performance:
R^2: 0.991521, RMSE: 0.160487
Done!
# performance metrics
perf = test(test_dataloader, model5, loss)
Test performance:
R^2: 0.992058, RMSE: 0.155241
# plotting actual values vs. predictions
ypred = model5(torch.from_numpy(np.float32(x_test)).to(device)).cpu().detach().numpy()
plt.scatter(ypred,y_non_test,s=.1)
plt.xlabel("Predictions");
plt.ylabel("Actual values");
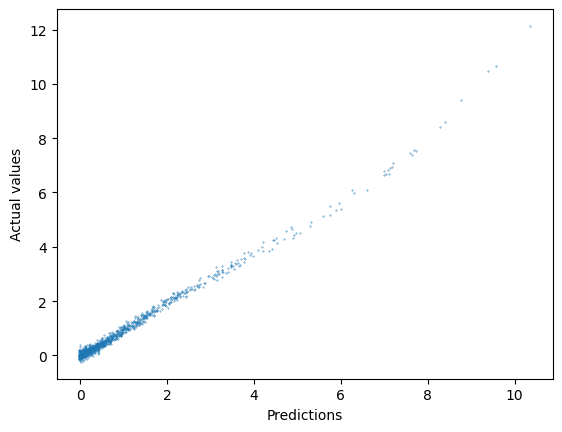
The bells and whistles buy us only a little bit of extra performance here, but this is a very simple case. In more complex, multivariate situations, these features can have a major effect on model performance.
Next steps#
This tutorial has provided a basic example of how one can create one’s own artificial neural network using pytorch. However, there’s a lot more that you can do with deep nets beyond what’s been shown here. This final section will point you to some directions for further learning that you may be interested in.
Other layer connectivity patterns#
The layers in the networks you’ve seen here are all “densely” connected. This means that every unit in one layer is connected to every unit in another layer. Most of the connections are also sequential, with the exception of the skip layer connection in the last model. However, there are a wide variety of other connectivity patterns that can perform better for particular applications. Several of these patterns are illustrated in the figure below.
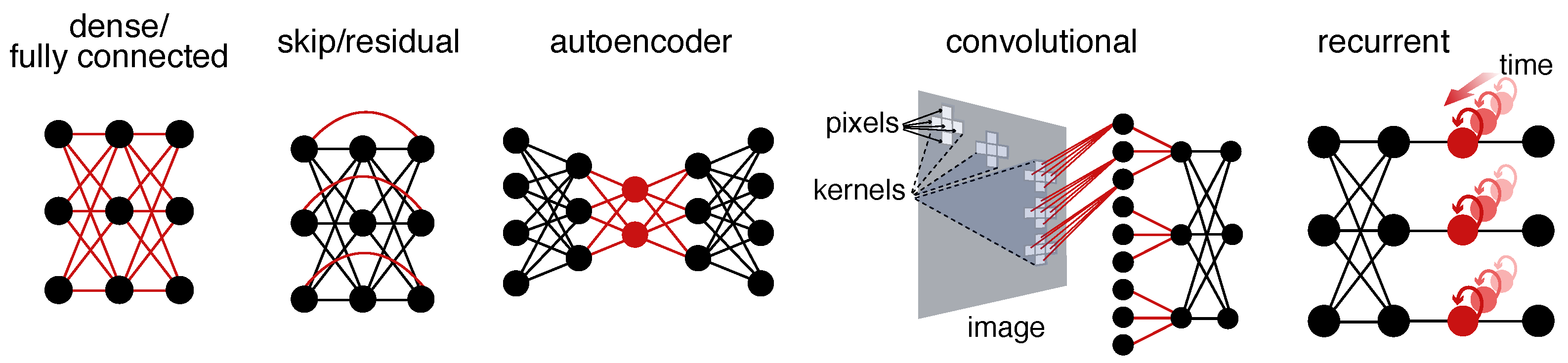
The bottleneck (red) in the autoencoder illustration is a layer that is narrower (i.e., has fewer units) than the ones before or after it. This forces this layer to learn a compressed representation of the data - a bit like PCA, but nonlinear, not (necessarily) orthogonal, and with potentially different loss functions than maximizing variance explained.
Convolutional networks are ubiquitous due to their effectiveness in dealing with image-like data (e.g., photos, video, fMRI, or even spectrograms of audio or electrophysiology). The connectivity pattern - and receptive fields that emerge - loosely approximate the human visual system.
Recurrent connectivity carries a unit’s activity forward from one time point to another. Long short-term memory (LSTM) networks are probably the best known example of this type. These models are most often used for time series and other sequential data.
Perhaps the most important type of unit/connectivity (not pictured due to its complexity) is the attention mechanism of transformer architectures. Transformers are beyond the scope of this introduction, but they support many of the most influential ANNs as of time of writing (e.g., all the major large language models like GPT).
Applications#
One way to organize your learning is to think about how you want to apply deep nets in your own research. The figure below illustrates some of the main uses cases that you might be interested in. These include (A) training statistical biomarkers to predict phenotypes from brain data, (B) using computer vision/audition models to annotate behavior in stimuli/recordings of participants, and (C) training models on the same tasks as participants, so that they can be used as cognitive models. Once you know which of these applications you want to use in your research, it can help you figure out where to go next. 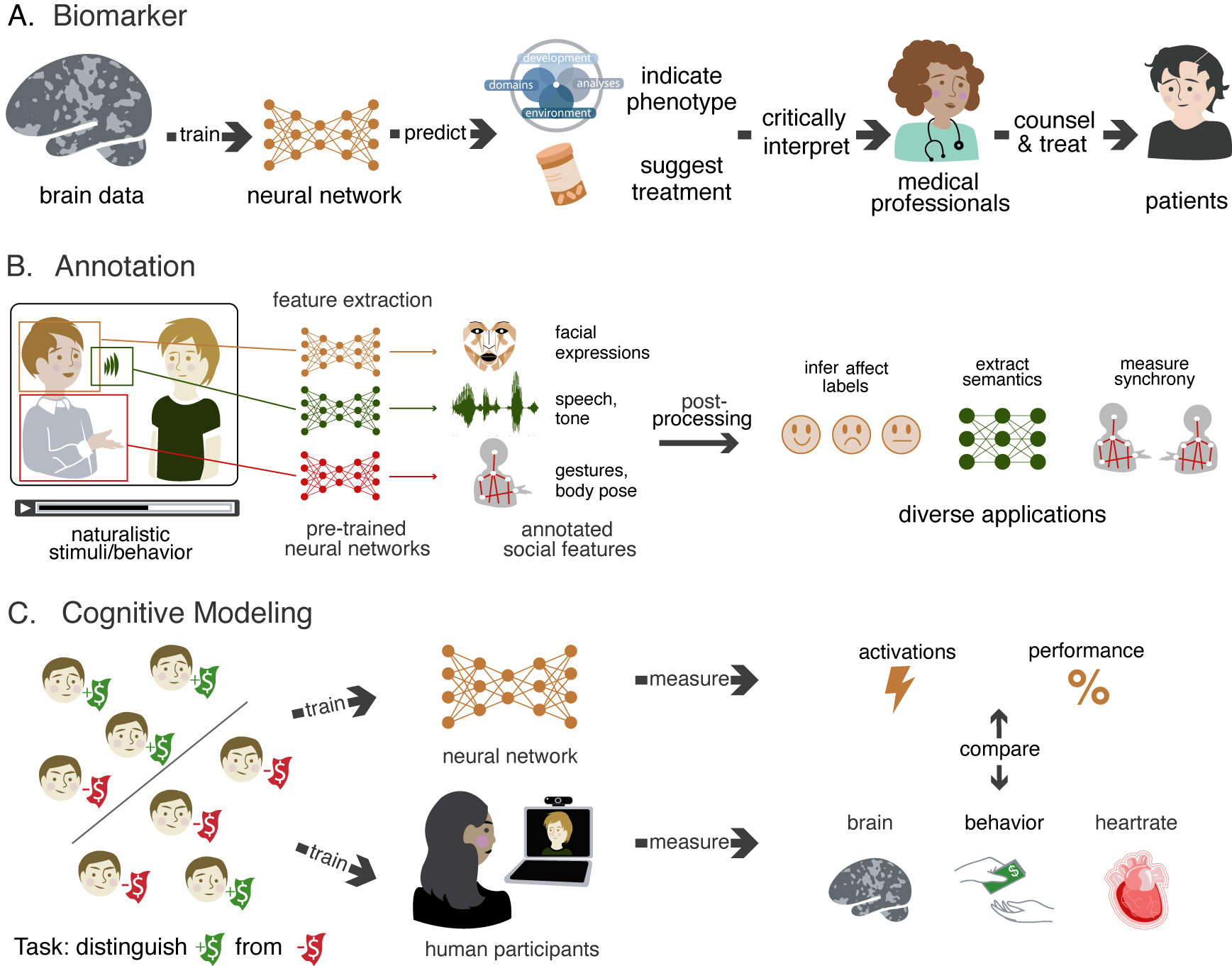
Learning resources#
Tutorial material:
Websites:
If you’re looking to find the best (pre-trained) model for a specific application, Paper’s with Code is in an extremely useful source. It tracks the state of the art with respect to a huge number of machine learning benchmarks, with links their papers and github repos.
Hugging Face is a model repository where an increasing number of popular pretrained models are uploaded. It provides a consistent API for installing, using, and documenting models, most of which are programmed in PyTorch and/or Tensorflow.
DeepMind Blog: Google DeepMind maintains a blog where they write about their papers in (relatively) accessible ways.
Videos:
Neuromatch’s video playlists on deep learning, and autoencoders,
Berkeley Deep Reinforcement Learning Bootcamp
Two minute papers Short, easily digested videos on recent modeling
Many of my favorite scientific papers on deep learning are cited within these two papers:
Thornton, M.A., & Sievers, B. (2023). Deep social neuroscience: The promise and peril of using artificial neural networks to study the social brain. PsyArXiv. Preprint
Lin, C., Bulls, L. S., Tepfer, L. J., Vyas, A., Thornton, M. A., (2023). Advancing naturalistic affective science with deep learning. Affective Science. Preprint